今天读到byte写的一篇blog,记录了一下vc当ä¸çš„时间表达方å¼ï¼Œéšæ‰‹å›žå¤äº†ä¸€ç¯‡ï¼Œå½“敲入mktime的时候,çªç„¶å¿ƒä¸ä¸€éœ‡ï¼Œæœ‰ä¸€ç§è¯¯äººåå¼Ÿçš„æ„Ÿè§‰ï¼Œå› ä¸ºæƒ³åˆ°äº†ä¹‹å‰ä¸€ä¸ªé¡¹ç›®å½“ä¸å¯¹äºŽæ—¶é—´å¤„ç†çš„问题的切肤之痛。
å½“æ—¶é‚£ä¸ªé—®é¢˜æ˜¯è¿™æ ·çš„ï¼šç¨‹åºä¼šè°ƒç”¨time函数得到time_t(这个是GMT时间è·ç¦»1970å¹´1月1日的秒数),然åŽç”¨localtime把它转æ¢æˆå¯è¯»çš„struct tmæ ¼å¼ï¼Œå³å¹´æœˆæ—¥æ—¶åˆ†ç§’çš„æ ¼å¼ï¼Œç„¶åŽæ ¹æ®å®ƒæ¥åˆ›å»ºæ–‡ä»¶å¤¹ï¼Œæ¯”如我现在时区是GMT+8,å³åŒ—京时间,凌晨3点32分,程åºå°±ä¼šåˆ›å»ºä¸€ä¸ªå为20070617\0332的文件夹,然åŽæŠŠä¸€äº›ä¸œè¥¿æ”¾åœ¨é‡Œé¢ã€‚过一会之åŽï¼Œç¨‹åºä¼šåŽ»æžšä¸¾æ‰€æœ‰çš„文件夹然åŽå¯¹å…¶ä¸çš„东西进行处ç†ï¼Œæžšä¸¾çš„时候,程åºä¼šæ ¹æ®è¿™ä¸ªç›®å½•çš„å—符串æ¥åˆ‡å¼€åšæˆä¸€ä¸ªstruct tmæ ¼å¼ï¼Œç„¶åŽè°ƒç”¨mktime去转æ¢æˆtime_t进行进一æ¥çš„处ç†ã€‚程åºä¼šä¼ 递这个time_t,并在必è¦çš„时候é‡æ–°æ ¹æ®å®ƒæ¥æ‰¾åˆ°æ–‡ä»¶æ‰€åœ¨çš„目录。简å•çš„逻辑å¯ä»¥è¿™æ ·è®¤ä¸ºï¼š
time_t now = time(NULL);
struct tm* tnow = localtime(now);
sprintf(szPath, "%4d%02d%02d\\%02d%02d",
tm->tm_year+1900, tm->tm_mon+1, tm->mday,
tm->tm_hour, tm->tm_min);
CreateDirectory(szPath);
// later
// find each directory to szPath, and get year, month, day, hour, min from the szPath.
// Then set struct tm dirTm;
time_t dirTime = mktime(&dirTm);
ProcessThem(dirTime);
void ProcessThem(time_t dirTime) {
struct tm* dirTm = localtime(dirTime);
szPath = getPathFromTime(dirTm);
// open the file
}
这个逻辑在ä¸å›½çš„区域设置下é¢æ¯«æ— é—®é¢˜ï¼Œä¸€åˆ‡éƒ½å¦‚é¢„æƒ³çš„ä¸€æ ·è¿è¡Œã€‚但是这个产å“还需è¦è¢«å–åˆ°ç¾Žå›½ï¼ŒåŒºåŸŸè®¾ç½®ä¸ºå¤ªå¹³æ´‹æ ‡å‡†æ—¶é—´çš„åœ°æ–¹ã€‚é‚£ä¸ªåœ°æ–¹æœ‰ä¸€ç§ä¸œè¥¿å«åšå¤ä»¤æ—¶ï¼ŒDaylight Saving Time, DST。æ¯å¹´çš„4月的第一个周日(现在已ç»æ˜¯3月的第二个周日了,这是今年的新规定,所谓的DSTE,为æ¤è¿˜æœ‰æ›´å¤šçš„I18N的麻烦,有机会å†è¯´ï¼‰ï¼Œå½“ç§èµ°åˆ°å‡Œæ™¨1:59:59过åŽï¼Œå¹¶ä¸æ˜¯æ£å¸¸çš„跳到2:00:00,而是å˜æˆ3:00:00。也就是说,钟快了一个å°æ—¶ã€‚到了10月的最åŽä¸€ä¸ªæ˜ŸæœŸå¤©ï¼ˆçŽ°åœ¨æ˜¯11月的第一个星期天)的钟表指到1:59:59之åŽï¼Œé’Ÿä¼šè·³åˆ°1:00:00,也就把钟调了回æ¥ã€‚
于是产å“在进入å¤ä»¤æ—¶ä¹‹åŽå‡ºäº†é—®é¢˜ï¼Œæ—¥å¿—当ä¸æŠ¥å‘Šäº†å¤§é‡çš„“找ä¸åˆ°æ–‡ä»¶â€é”™è¯¯ã€‚ç»è¿‡åˆ†æžå‘现,在上é¢çš„逻辑当ä¸ï¼Œåœ¨å¤ä»¤æ—¶åˆ‡æ¢ä¹‹åŽï¼Œæ¯”如钟表时间3:01:00(实际上物ç†æ—¶é—´æ˜¯2:01:00),第一个localtime的调用创建了一个å为20060402\0301的文件夹,之åŽæ ¹æ®è¿™ä¸ªè·¯å¾„åˆå§‹åŒ–struct tm dirTm,但是struct tm当ä¸çš„tm_idst域并没有赋值(也就是0),所以调用mktime的时候,这个函数会把struct tm结构当ä¸çš„值当作éžå¤ä»¤æ—¶ï¼Œè¿™æ ·è½¬æ¢å›žçš„time_t就指到了物ç†æ—¶é—´çš„3:01:00,之åŽå†æ¬¡è°ƒç”¨localtime,获å–çš„struct tm当ä¸ï¼Œtm_hourå˜æˆäº†4ã€‚è¿™æ ·ä¸€æ¥ï¼Œç¨‹åºè¯•å›¾åŽ»20060402\0401下é¢åŽ»å¯»æ‰¾æ–‡ä»¶ï¼Œè¿™å°±å¯¼è‡´äº†å¤§é‡çš„找ä¸åˆ°æ–‡ä»¶çš„错误。
解决的方法有两个,一个是åˆå§‹åŒ–struct tm dirTm的时候,将tm_idst设æˆè´Ÿæ•°ï¼Œä¾‹å¦‚-1ï¼Œè¿™æ ·mktimeä¼šæ ¹æ®å½“å‰æ—¶åŒºæ¥å†³å®šæ˜¯å¦æ ¹æ®å¤ä»¤æ—¶è¿›è¡Œæ ¡å¯¹ã€‚å¦ä¸€ç§æ–¹æ³•æ˜¯å®Œå…¨ä½¿ç”¨GMT函数替æ¢æœ¬åœ°æ—¶é—´å‡½æ•°ã€‚例如localtime->gmtime,mktime->_mkgmtime。
这个问题本质上就是一个软件的I18N问题。I18N=Internationalization,å³å›½é™…åŒ–ï¼Œå› ä¸ºIå’ŒNä¸é—´æœ‰18个å—符而得å,类似的还有L10N(Localization,本地化),以åŠG11N(Globalization,全çƒåŒ–)。软件的I18N问题之所以æˆä¸ºä¸€ä¸ªé—®é¢˜ï¼Œæ˜¯å› 为这个世界上有接近200个国家和地区,2000多个民æ—,4200多ç§è¯è¨€ï¼Œä»¥åŠï¼Œåœ°çƒæ˜¯åœ†çš„。
应该庆幸我们生活在ä¸å›½ï¼Œå› 为ä¸å›½çš„很多东西都很简å•ï¼Œå°¤å…¶æ˜¯ç‰µæ¶‰åˆ°è½¯ä»¶I18N的时候。没错,å¯ä»¥è®¤ä¸ºä¸å›½æœ‰ä¸–界上最大的å—符集,最å¤æ‚çš„æ–‡å—表达方å¼ï¼Œä½†æ˜¯æˆ‘们的时区是GMT+8,没有零头,没有å¤ä»¤æ—¶ï¼›ä¸æ–‡çš„ç¼–ç GB2312å’ŒGB18030éƒ½æ˜¯ä¸Šä¸‹æ–‡æ— å…³çš„ç¼–ç ,而且广泛使用的GB2312还是定长的编ç (两个å—节一个汉å—),而且任何å—节ä¸ä¼šå’Œ7ä½ASCIIç é‡å ï¼›æˆ‘ä»¬ä½¿ç”¨æ ¼åˆ—é«˜é‡ŒåŽ†æ³•ï¼Œä½¿ç”¨å…¬å…ƒçºªå¹´ï¼›æˆ‘ä»¬çš„é»˜è®¤é”®ç›˜å¸ƒå±€æ˜¯æ ‡å‡†101é”®qwerty键盘;我们的文å—åƒä¸–界上ç»å¤§å¤šæ•°æ–‡å—ä¸€æ ·ä»Žå·¦å‘å³æ¨ªå‘书写……所有这一切对于写软件的人æ¥è¯´æ˜¯è¿™æ˜¯å¤šä¹ˆç¾Žå¥½çš„一件事情啊。我们å¯ä»¥èŽ·å–当å‰çš„时间,å˜å‚¨å…¶å¹´æœˆæ—¥æ—¶åˆ†ç§’,将æ¥æ— 论什么时候拿到这个年月日时分秒,都ä¸ä¼šæœ‰ä»€ä¹ˆé—®é¢˜ï¼›æˆ‘们å¯ä»¥åœ¨ä¸€ä¸ªä¸æ–‡ç¼–ç çš„å—符串当ä¸è‚†æ„地用strchr查找’\\’æ¥åˆ‡å‰²æ–‡ä»¶è·¯å¾„,而ä¸ç”¨æ‹…心0x5C在当å‰çš„上下文当ä¸æ˜¯è¡¨ç¤ºå斜线还是日元符å·ï¼ˆåœ¨æ—¥æ–‡ç¼–ç shiftJIS当ä¸ï¼Œæ—¥å…ƒç¬¦å·çš„ç¼–ç å’ŒASCII当ä¸å斜线编ç é‡å ,都是0x5C,这ç§é—®é¢˜åœ¨GB系列编ç ä¸ä¸ä¼šå˜åœ¨ï¼‰ï¼›è¿˜æœ‰ï¼Œæˆ‘们的å°æ•°ç‚¹å°±æ˜¯åœ†ç‚¹ï¼Œè´Ÿæ•°å°±æ˜¯åœ¨æ•°å—å‰é¢åŠ 上负å·ï¼Œè€Œä¸æ˜¯ç”¨é€—å·è¡¨ç¤ºå°æ•°ç‚¹ï¼ˆå¾·æ–‡åœ°åŒºæ˜¯è¿™æ ·çš„),而且ä¸ä¼šç”¨æ‹¬å·è¡¨ç¤ºè´Ÿæ•°ï¼ˆæ¬§æ´²æŸåœ°å¦‚æ¤ï¼Œä¸è®°å¾—哪国了)。
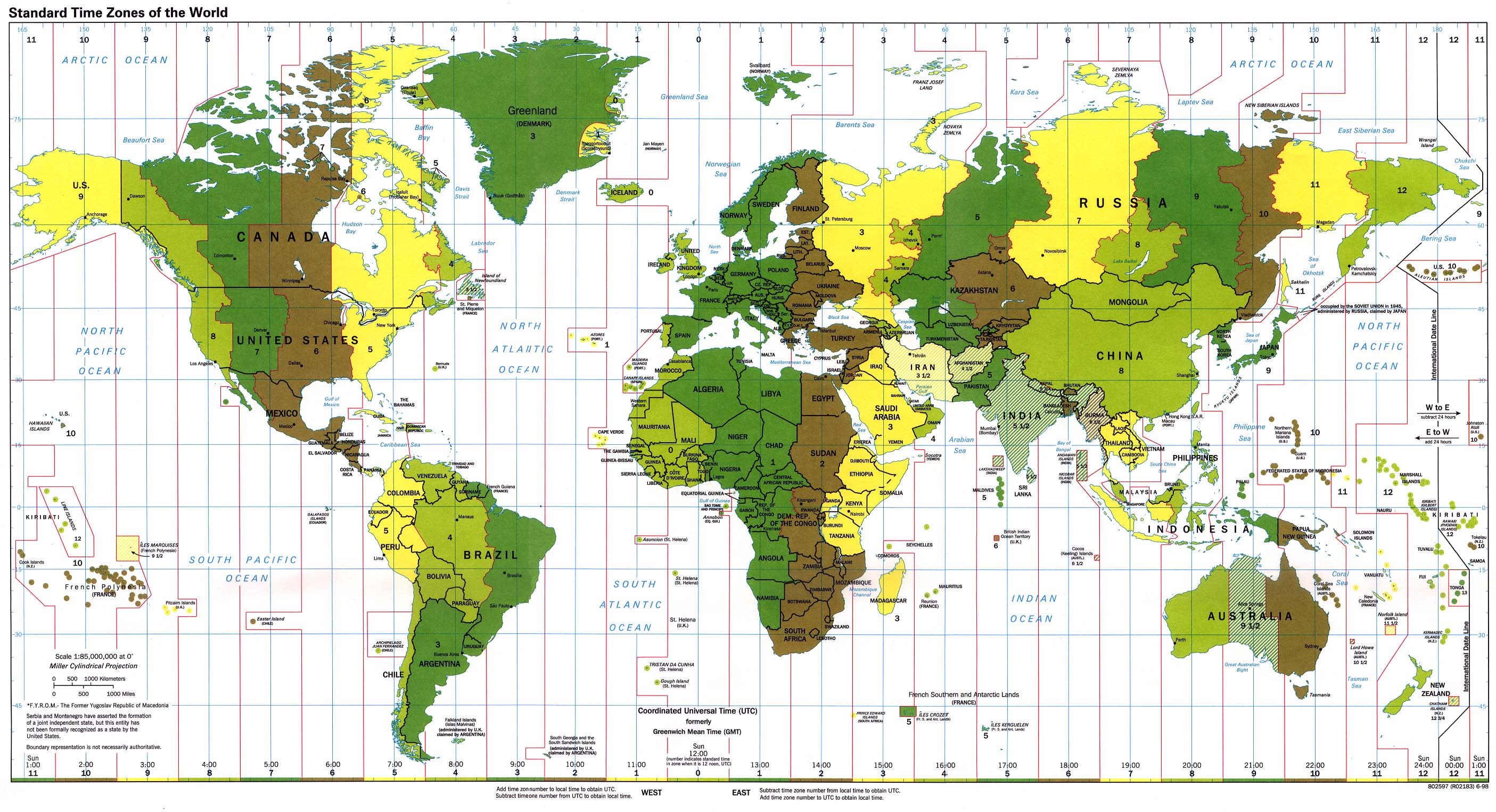
ä½†æ˜¯è¿™æ ·ä¹Ÿä¼šè®©æˆ‘ä»¬ä¸å›½çš„软件工程师低估了软件I18N的难度:ä¸æ˜¯æ‰€æœ‰å›½å®¶çš„人们的时间都是连ç»çš„,很多国家在使用å¤ä»¤æ—¶ï¼›å¾ˆå¤šå›½å®¶æˆ–地区ä¸ä½¿ç”¨å…¬å…ƒçºªå¹´ï¼Œæ¯”如日本和å°æ¹¾ï¼›è¿˜æœ‰äº›åœ°æ–¹ä¸ä½¿ç”¨æ ¼åˆ—高里历法,例如ä¸ä¸œçš„很多国家。说起时间,时区也ä¸ä¸€å®šæ€»æ˜¯ä¸œå…«åŒºï¼Œè¥¿äº”区这么简å•ã€‚å°åº¦å¤§éƒ¨åˆ†åœ°åŒºéƒ½æ˜¯GMT+5.5,尼泊尔是GMT+5.75;太平洋上æŸå²›å›½(TONGA)是GMT+13,这是全çƒæœ€æ—©çš„时间;ä¸ä¸œæŸå°å›½ç”±äºŽå®—æ•™åŽŸå› æ—¶åŒºæ˜¯GMT-89,也许是全çƒæœ€æ™šçš„时间了。å¯ä»¥çœ‹çœ‹è¿™å¼ å…¨çƒæ—¶åŒºåˆ’分图æ¥çœ‹çœ‹æœ‰å¤šå°‘诡异的时区å§ï¼ˆè¿™å¼ 图有些è€ï¼Œ98年的,所以很多诡异的都还没有,ä¸è¿‡å·²ç»å¤Ÿå¤šäº†ï¼‰ã€‚
而谈åŠè¯è¨€ç¼–ç ,那åˆæœ‰äº†æ›´å¤šçš„问题,现在太晚了,有空å†å†™ã€‚

{kind=link}